There are many ways to understand data mining and there are several tutorials on the subject. Dr. Susan Holmes at Stanford has been teaching and practicing different statistical methods and has significant insight into the process of teasing out information from complex data sets.
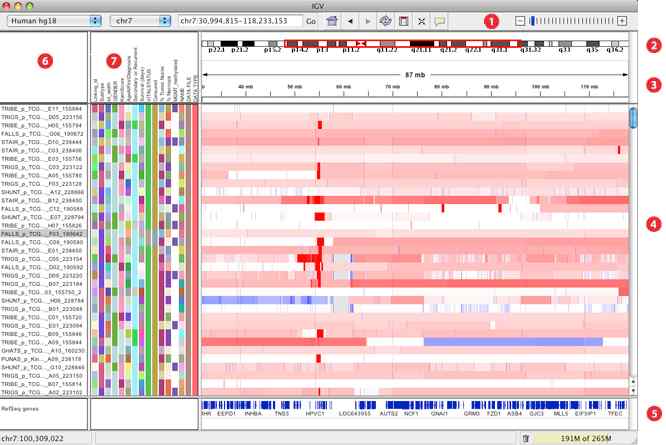
She made an interesting observation in “The Theory that would not die” by Sharan Bertsch Mcgrayne. Microarrays are used commonly in gene expression profiling and it measures which genes are turned on and which are turned off. It usually measures the amount of RNA that is produced by cells or tissue in an organism. So, if you get a signal for gene X it means that the gene is expressed. When you look at the profile for a set of 20,000 genes, you get very complicated data that shows how some genes are expressed and how some genes are suppressed. This data is very hard to interpret and statistician spend significant amount of time trying to understand the data. This is especially complicated since the genes are switched on/off dependent on many factors that cannot be quantified or are unknown’s.
One way to imagine this is like looking at a city from an airplane and seeing the lights that go ON and OFF. From the airplane you cannot tell whether the lights are related or why they change. However, your job is to figure out how this data is meaningful in the context of how the people turning on and off the lights are related to each other. Using this sparse data set that is loaded with noise to tease out relationship is a data mining challenge that Usin’Life scientists deal with every day.